OSM地図アプリは満11年目を迎えている。当初の4、5年は osm2pgsql により、OSMデータを PostgreSQL/PostGIS データベースに インポートして、Mapnikによりレンダリングしてタイル地図画像ファイルを作成していた。
osm2pgsql や Mapnik が Windows OS では使えない時期もあり、VirtualBox 上の Ubuntu で実行していたこともある。
このように、多数のフリーソフトを使っていると、それぞれのバージョンアップに振り回され、また、osm2pgsql や Mapnik による OSM地図のカスタマイズにも苦労が伴う。
そのため、フリーソフトには頼らず、自作プログラムによるレンダリングに切り替えた。Windows タブレットに地図アプリを搭載していた ときは C# プログラム、スマホに変えてからは Java プログラムである。
空間検索、空間インデックスについては、ネットで調べてもよく理解できず、簡単なメッシュ分割法を採ってきた。
Mapnikを使っていたときは、パソコンで大量のタイル画像ファイルを予め作成しておき、それを Windowsタブレットにコピーしていた。
スマホでは、実時間で、タイル画像を作成して、それを表示している。一度、作成したタイル画像が保存しており、 保存したタイル画像があれば、まずは、それを表示している。
元となるOSMデータが更新されていた場合、バッググラウンドで新しいタイル画像を作成し、出来上がったら、表示を切り替えている。 このため、保存タイル画像が十分にあれば、レンダリングに多少時間がかかっても問題はない。
また、現状では、空間検索よりもレンダリングそのものに時間がかかるため、空間検索時間の短縮は喫緊の課題ではない。
しかし、プログラムを少しでも分かりやすくしたいため、空間検索の改善を検討したい。
保存タイル画像の管理方法は階層ディレクトリから zip 、そして Mortonコードによる独自アーカイブ方式へと変更してきた。 Mortonコードも空間検索の一種である。
SQLiteでも R-Tree はサポートされているようであるから、レンダリングに使う OSMバイナリレコードを SQLiteにインポートする案もある。
事前に境界ボックスの中心座標のモートン順序で並び替えてインポートする必要があるようだ。 モートン順序よりもヒルベルト順序の方がいいようだ。
SQLite を使わず、自作する場合、モートン順序の方が簡単である。R-Treeインデックスがどのようになるかを見てみたい。 タイル画像や現在のOSMバイナリレコードの管理では、モートン順序で十分な結果を得た。
Windows 11 の SQLite は R-Tree をサポートしているようであるが、 Android スマホではサポートしていなかった。 Android Studio をあれこれいじくると、これまで動いていたものが動かなくなる恐れがあるので、 非標準的な使い方は極力避けたい。
データベースとは無関係にメモリ上の R-Tree プログラム[1]があったので、これを使ってみることにした。
Android Java 用であるため、RectF が使われていた。これを Rectangle に置き換えた。 RectF では left, top, right, bottom が Rectangle では x, y, width, height に変わる。 また、メソッドの仕様も異なる。RectF.intersects(RectF a, RectF b) は Rectangle#intersects(Rect a) に 変えた。RectF#union(RectF a) は 自分の値を変更するが、Rectangle#union(Rectangle a) は変更しない。 したがって、 rectA.union(rectB); は rectA = rectA.union(rectB); に変更した。
また、area() の算出は float で行うように (float)width * height とした。 float を long に変えてもいいが、修正箇所が多いのでこうした。
最終的な検索テストでは下のように(東京)にした。
Treeの子ノードの最小値は 10、最大値は 100 とした。 関東データでは、最大値は 10, 20, 100 に変えてテストしたが、有意差はなかった。
Rectangle box = new Rectangle(1397815420, 357146010, 230000, 180000);
Collection<BoundedObject> results = new ArrayList<>();
query(results, box);
日本全体では約4,700万レコードとなり、同じ検索を10回繰り返した結果を下に示す。
関東データでは1,000万レコード強であるが、検索時間に差はなかった。
なお、ここでは、インポートするレコードの境界ボックスの中心座標 (x, y) をビット単位でインタリーブした long値で並び替えて(モートン順序) R-Treeに 読み込ませた。この並び替えなしでは検索時間は 15、16mSとなった。
いずれ、レコード本体自体をモートン順序で並び替える。そうしないと、 検索時間は速くても、レコードの読み出しに時間がかかってしまう。
R-Tree作成完了 46880248 size=27762 6mS size=27762 4mS size=27762 1mS size=27762 0mS size=27762 4mS size=27762 0mS size=27762 5mS size=27762 2mS size=27762 0mS size=27762 0mS java.awt.Rectangle[x=1035585008,y=11205354,width=530998120,height=498341715]
平均レコードサイズは 90.1Byte である。
R-Treeの有効性は十分に理解できた。 メモリ上に作られた R-Tree をファイルに書き込む必要がある。
スマホのアプリが使用できるメモリ容量は限られているため、 R-Treeの全ノードをメモリに読み込むことは難しい。 末端の葉ノード(子はレコード本体)のみは、キャッシング(入れ替え対象)して、 途中の全ノードはメモリに常駐させることを考えている。
葉ノードが平均的に 50レコードを束ねるとすれば、葉ノード数は現状では 100万 となる。
今回のプログラム(メモリ上)では、中継ノード(根を含む)と葉ノードは同じであるが、 ファイル上では変えることもできる。
中継ノードのポインタは4バイト、葉ノードのポインタは8バイトとする。
中継ノードには MBR(境界ボックス)が必須であるが、 葉ノードはレコード本体を指すポインタだけでもよい。レコード本体にもつ境界ボックスを使う。 その分、検索時間は増える。
ファイル上、葉ノードに境界ボックスを持ち、レコードには待たないようにする案もある。 葉ノードとレコードの両方に持つのがシンプルであるが、境界ボックスは 4x4=16バイトであり、 これだけで、レコード全体の2割程度を占める。
しかし、分かりやすさとパフォーマンスから当面は葉ノードとレコード本体の両方に境界ボックスを 持たせる。
将来は一体化するかもしれないが、まずは、R-Treeインデックスファイルとレコード本体ファイルは 別物とする。インデックスファイルは 中継ノードは length(2)、type(2)、{ 子ノードoffset(4)、MBR(16) }、 葉ノードは length(2)、type(2)、{ (レコードoffset(8)、MBR(16) } とする。
葉ノードの総エントリ数を 5,000万(50M) とすると、インデックスファイル上のサイズは 1.2GB になる。 中継ノード数は 100~200万に抑えることができるであろう。ファイルサイズ上は 20~40MB となるので、 地図アプリのメモリに常駐できる大きさである。 オフセットを8バイトに統一しても、24~48MB である。
また、葉ノードと同様にキャッシュに置き、入れ替えれば、メモリ使用量は少なくて済む。
レコードファイルとインデックスファイルを分離した場合、レコードの決定は瞬時に行えても、 レコードの取り出しに時間がかかると意味はない。
OSMバイナリレコードの平均レコードサイズは 90バイトと小さい。 中には巨大なレコードもある。例えば、256バイトを超えるものは別扱いとする案もあるが、 その分、プログラムが複雑となる。
葉ノードにレコードを直接置くと、より一層、境界ボックスの重複が気になるが、まずは、 そのまま、重複させておく。
葉ノードは平均50レコードとすると、その平均サイズは (16 + 90) x 50 = 5,300 となる。
ファイルの書き込みは root から順に実行してみる。
簡単な深さ優先で順に出力する。葉ノードは後から出力するため、リストに入れておく。 ファイルの先頭には葉ノードの始まりのオフセットを書き込む。
ファイル書き込みの前処理として、中継ノードと葉ノードをそれぞれリスト出力して、 ファイル上のオフセットを事前に算出しておく。
結果は以下の通り。全中継ノードのサイズは 15.4MB であるから、楽に、メモリに常駐できる。
葉ノードはキャッシュに置くが、最大で 0.5MBである。平均では 4.65GB/0.8M=5.8KB である。 平均レコード長+管理データは 106バイトであるから、葉ノードの平均レコード数は 55 程度である。
葉ノードはレコード本体を含んでおり、キャッシュにおく。 一般に、大きな葉ノード(サイズの大きいレコード)ほど共用されるので、 キャッシュ効果を発揮できよう。
Node: 14090 15.4MB Leaf: 789946 最大サイズ 0.5MB ファイルサイズ 4.65GB
オブジェクトを取り込んでツリー構造状に配置するプログラムは全体では、それなりの行数になるが、 ツリー構造を辿って所望のデータを得るのは極めて簡単である。
レンダリングの場合、タイルの矩形範囲にある全レコードを抽出すればいいので、そのプログラムは 以下のようになる。
public void query(Collection<BoundedObject> results, Rectangle box) {
query(results, box, root);
}
private void query(Collection<BoundedObject> results, Rectangle box, Node node) {
if (node == null) return;
if (node.isLeaf()) {
for (int i = 0; i < node.data.size(); i++)
if (node.data.get(i).getBounds().intersects(box))
results.add(node.data.get(i));
} else {
for (int i = 0; i < node.children.size(); i++) {
if (node.children.get(i).box.intersects(box)) {
query(results, box, node.children.get(i));
}
}
}
}
最終的なレコードではなく、それを含む葉ノードを抽出する場合には、次のようになる。
public void queryLeaf(Collection<Node> results, Rectangle box) {
queryLeaf(results, box, root);
}
private void queryLeaf(Collection<Node> results, Rectangle box, Node node) {
if (node == null) return;
if (node.isLeaf()) {
results.add(node);
} else {
for (int i = 0; i < node.children.size(); i++) {
if (node.children.get(i).box.intersects(box)) {
queryLeaf(results, box, node.children.get(i));
}
}
}
}
まず、kanto.dat で最大子ノード数が 100 と 200 でテストした。
実際の使用では、該当リーフ(レコードを含む)をキャッシュして、 ここから、レコード毎に境界ボックスをチェックして、該当レコードを取り出すが、 ヒット率は高く、該当しないものはあまりない。
I/O回数を減らしたいの最大ノード数は大きい方がよいようだ。
最大ノード数の適正値は地図アプリに検索プログラムを実装してから検討するが、 とりあえずは、200 としておく。
最大子ノード数=100 RTree作成完了 10361215 27759データ 0mS 27759データ 0mS 27759データ 0mS 27759データ 16mS 27759データ 0mS 27759データ 0mS 27759データ 0mS 27759データ 16mS 27759データ 0mS 580リーフ 0mS 580リーフ 0mS 580リーフ 0mS 580リーフ 0mS 580リーフ 0mS 580リーフ 0mS 580リーフ 0mS 580リーフ 0mS 580リーフ 0mS 580リーフ 0mS java.awt.Rectangle[x=1035585008,y=11205354,width=459684079,height=415165948] Node: 3047 3.4MB Leaf: 173158 最大サイズ 0.1MB ファイルサイズ 0.98GB 最大ノード数=200 RTree作成完了 10361215 27759データ 6mS 27759データ 0mS 27759データ 0mS 27759データ 0mS 27759データ 9mS 27759データ 0mS 27759データ 0mS 27759データ 0mS 27759データ 0mS 326リーフ 0mS 326リーフ 0mS 326リーフ 0mS 326リーフ 0mS 326リーフ 0mS 326リーフ 0mS 326リーフ 0mS 326リーフ 0mS 326リーフ 0mS 326リーフ 0mS java.awt.Rectangle[x=1035585008,y=11205354,width=459684079,height=415165948] Node: 781 1.7MB Leaf: 87686 最大サイズ 0.2MB ファイルサイズ 0.98GB
japan.dat では最大子ノード数は200とした結果を下に示す。結果データ数が kanto.dat の結果より わずかに大きいのは、japan.dat の方が少し新しい日付のデータで OSM データ自体が少し大きくなった ことによる。また、実際のレンダリング結果には現れないが、kanto.osm にはないような、 巨大な境界線が japan.osm には含まれることがある。
個々のタイルのレンダリング結果には現れない巨大なレコードがレンダリング時間を長くするので厄介である。
過去には、境界線のほか、航路がこれに該当した。陸地タイルのレンダリングにも航路レコードが 含まれる。細かく区切った多数のレコードではなく、全体を一つのレコードとしていると、 その境界ボックスは巨大となり、陸地タイルのレンダリングにもこのレコードが含まれる。
このようなことから、日本全体のデータと関東地方のデータには差異が生まれる。
RTree作成完了 46880248 27762データ 2mS 27762データ 0mS 27762データ 9mS 27762データ 5mS 27762データ 2mS 27762データ 0mS 27762データ 0mS 27762データ 0mS 27762データ 0mS 332リーフ 0mS 332リーフ 13mS 332リーフ 0mS 332リーフ 0mS 332リーフ 0mS 332リーフ 0mS 332リーフ 0mS 332リーフ 0mS 332リーフ 0mS 332リーフ 0mS java.awt.Rectangle[x=1035585008,y=11205354,width=530998120,height=498341715] Node: 3574 7.7MB Leaf: 400137 最大サイズ 0.4MB ファイルサイズ 4.64GB
332リーフノードに該当する 27,762レコードが含まれるので、平均 83.6レコード/リーフとなる。 全体では 46880248/400137=117.2 であるから、 検出されたリーフには 29%の該当しないレコードが含まれていることになる。
リーフの平均サイズは 4640MB/0.4M=11.6KBであるから、332リーフは 4MB弱である。
今回は調べていないが、同じ親に属するリーフが多いであろう。 リーフの親から見たサイズは 1~2MB であろう。リーフ単位のキャッシングでなく、 その親単位のキャッシングにすれば、I/O回数は大きく減らせるであろう。
その代わりに、最大ノード数を 2000 にしてみた。ツリーの構築にはるかに時間がかかるようになった。 処理時間的には 100~200 が適当であろう。
結果は以下のようになった。リーフの総数は 1/10 に減ったが、検索結果のリーフ数は 1/4 になっただけである。
I/O回数を減らすにはやはり別の方法を考えるべきである。
最大子ノード数200で得られた 332リーフは互いに近い位置にあるはずである。 中間に該当しないリーフが多少含まれていてもいいので、まとめて一括して読み込む。 キャッシュにはリーフ単位で登録する。今回のタイルのレンダリングで使わなくても、 別のタイルのレンダリングで使われる可能性がある。
RTree作成完了 46880248 27762データ 16mS 27762データ 16mS 27762データ 0mS 27762データ 0mS 27762データ 0mS 27762データ 0mS 27762データ 16mS 27762データ 0mS 27762データ 0mS 79リーフ 0mS 79リーフ 0mS 79リーフ 0mS 79リーフ 13mS 79リーフ 0mS 79リーフ 0mS 79リーフ 0mS 79リーフ 0mS 79リーフ 0mS 79リーフ 0mS java.awt.Rectangle[x=1035585008,y=11205354,width=530998120,height=498341715] Node: 45 0.8MB Leaf: 40601 最大サイズ 0.8MB ファイルサイズ 4.63GB
最大子ノード数=200、最小=10 とする。葉ノードは length(4バイト),レコード1,レコード2, ... ,レコードN とする。 境界ボックスはレコードに含まれているので、それで該当レコードかどうかを判定する。
R-Tree化によるファイルサイズの増加は微々たるものになる。
葉ノード全体を一つのものとして、キャッシュに入れ、キーは葉ノードのオフセットとする。 検索出力は葉ノードオフセットのリストである。
過去にレンダリングしたタイル画像がある場合、更新頻度は抑制している。 したがって、葉ノードの全レコードがレンダリングに使われるとは限らない。 そのため、最初の読み込みでは Record の byte配列にセットする。 空間検索のための 境界ボックス値は4つの int にセットする。 レンダリングに使うとなったときは、パースを進める。
パース結果を何度も使う可能性はある。zoom を変えても、通常は同じレコードが使われる。 レンダリングでは zoom は低、中、高の3段階に分けているので、これが変わったときは 異なるファイルにあるレコードに変わる。キャッシュにはこれらのレコードが混在するため、 キャッシュのキーには name (japan, kanto, lands など) と range(high, mid, low) を offset の前に置き、全体を 8 バイトとする。
出力ファイルが元のファイルより5%ほど小さくなった。少し、大きくなるはずなので、 どこかにバグがあるのであろう。
offsetRafをセットした段階では目立つ異常はないので、出力に問題があるのであろう。
レコード長の出力が漏れていた。これを修正した結果、kanto_high.dat 839MB に対して kanto_high.obr 841MB となった。サイズとしては妥当な結果となった。
次に、スマホの地図アプリ側のプログラムを作る。
スマホはメモリ使用量が制限されていることから、Nodeオブジェクトの tree とはせず、 ファイル上の中身をそのまま int配列として、ポインタ(インデックス)で辿るようにした。
検索プログラムを以下に示す。葉ノード
public void query(Collection results, Rect box) {
query(results, box, 1);
}
private void query(Collection results, Rect box, int ix) {
if (ix >= ia.length || ix < 0) return;
int length = ia[ix++] / 4; // offset を int配列の添え字に変換する
length -= 1; // length の分
for (int i = 0; i < length/6; i++) {
int high = ia[ix];
int low = ia[ix+1];
long offsetChild = ((long)high << 32) | (low & 0xFFFFFFFFL);
Rect boxChild = new Rect(ia[ix + 2], ia[ix + 3],
ia[ix + 2] + ia[ix + 4], ia[ix + 3] + ia[ix + 5]);
if (Rect.intersects(boxChild, box)) {
//System.out.println(ix + ": " + boxChild);
if (offsetChild/4 >= ia.length) { // 葉ノードを指す
results.add(offsetChild);
} else {
query(results, box, (int)offsetChild/4);
}
}
ix += 6;
}
}
kanto.obr に対して次の結果を得た。326リーフはパソコンでのテスト結果と一致している。 同じ検索を10回実行した検索時間は十分に満足いくものである。
今回は、検索された葉ノード(レコードを含む)の読み込みだけをテストした。
kantoでは、326葉ノードの合計サイズは 3MB強、読み込み時間は 22mS となった。
japanでは、葉ノード読み込み時間が極端に増えた。 検索時間は問題ないが、レコード読み込みに問題がある。 一部の葉ノードが離れた場所にあり、seek に時間がかかっているものと思われる。 SDカードはハードディスクとは異なり、シークに時間がかからないと思っていたが、 そうでもないのかも知れない。ファイルの断片化が関係しているかも知れない。
kanto load 14133mS 326リーフ 5mS 4mS 4mS 4mS 4mS 1mS 0mS 0mS 0mS 1mS 3.075MB 22mS
japan load 95700mS 332リーフ 1mS 1mS 1mS 1mS 0mS 0mS 1mS 1mS 1mS 1mS 3.465MB 732mS
まず、R-Tree部ロード時間の短縮を図った。数百倍速くなった。 RandomAccessFile を DataInputStream dis = new DataInputStream( new BufferedInputStream(new FileInputStream(file))) に変えた。
load 293mS 332リーフ 6mS 6mS 5mS 5mS 1mS 0mS 0mS 0mS 1mS 0mS 3.465MB 395mS
葉ノード(レコード群)読み込みも RandomAccessFile を DataInputStream dis = new DataInputStream( new BufferedInputStream(new FileInputStream(file))) に変えた。読み込み時間は大幅(1/30)に短縮した。
これで、R-Tree に置き換える見通しがついた。
load 9.3MB 292mS --- この値は、後述のように 18mS に短縮した 332リーフ 6mS 5mS 5mS 6mS 0mS 0mS 1mS 0mS 0mS 0mS 3.465MB 13mS
R-Tree部のロード時間は次のように替えるとわずか 18mS になった。
ファイルを二度読みしている。最初に4バイトだけ読み、R-Tree部のサイズを求めている。
次にそのサイズ分を一度に byte配列に読み込み、ByteBufferを使って、int配列に変換している。
一般に、I/O命令の実行回数を極力減らせば、高速化が図れる。
空間検索時間についても、得られる葉ノードは連続している部分が多いため、この連続部分を 一回のI/O命令(read)で実行するように替えれば、更に若干の高速化が図れる。 しかし、レンダリングではこの後の処理時間が大きいため、 これ以上短縮しても全体としての効果はごく小さい。
int load(String file) { // 中継ノードのみ
int length = 0;
try (DataInputStream dis = new DataInputStream(new FileInputStream(file))) {
length = dis.readInt();
} catch (IOException e) {
e.printStackTrace();
return 0;
}
try (DataInputStream dis = new DataInputStream(new FileInputStream(file))) {
byte[] bytes = new byte[length];
ia = new int[length/4];
int read = dis.read(bytes); // 必要ならば read == length をチェック
ByteBuffer.wrap(bytes).asIntBuffer().get(ia);
} catch (IOException e) {
e.printStackTrace();
return 0;
}
return length;
}
リーフノードは平均的には100~200個のOSMバイナリレコードである。リーフノードを class Leaf、 レコードオブジェクトを class Record とすると、 Leaf の主メンバーは Record[] records となる。
Record の最初のメンバーは OSMバイナリレコードをそのまま byte配列としたものである。
Leaf オブジェクトはキャッシングされ、レンダリングでは何度か共用される。
最初にレコードを利用するとき、byte配列をパースして、レンダリングに備える。
同じzoomでも共用されるが、zoom が変わっても共用される。 OSMタグは、タイル座標(zoom, x, y) に関係しないが、点、線(折れ線)、多角形などを 描画するときの座標は異なる。
OSMバイナリレコード上では、経度、緯度であるが、最終的な描画では X, Y 座標である。
zoom の値を低中高の3段階あるいは低高の2段階に分けて、使用するファイルが異なる。 高zoom では、現在、最高ズームを 21 としている。この場合はひとまず、 zoom 21 の世界平面XY座標に変換する。XY座標値としては タイル座標(x=0、y=0) とした値を算出する。 日本のタイル座標は、0 よりはるかに大きい値である。 レンダリングではそのタイル座標の左上のX,Y座標を引き算したものを使う。 zoom 20の場合には、まず、zoom21での世界平面XY座標を 2 で割ってから、タイル原点座標を減じる。
zoom 19 では、4(=22) で割ってから、タイル原点座標を減じる。
実際のレンダリングでは座標値は float 型となるが、割り算により、精度が落ちるため、 元となるXY座標値は double型とする。
ベースは zoom = 0 の値とした方が理解しやすいが、その場合、例えば、zoom 16 のレンダリング では 216 という大きい値をかけることになる。 double型では精度が落ちても float型を超える精度を保持できるので、こうするかも知れない。
異なるzoomでの共用を考えない場合は float 型の方がメモリ使用量が半減する。
float型でも問題はないような気もする。実際どうなるかは、実装してから、両者の数値を比較してみる。
現在はこのような形での共用は行っていない。上記の方法により、レンダリング前処理の時間短縮が 期待できる。
しかし、レンダリング自体の処理時間が全体を占める比重が現在も5,6割を超える。 このレンダリング時間の短縮は簡単ではない。
タグのパースは後で行う。
テスト結果の最初のレコードは length = 398, type = 1、次は length = 46, type = 0、osm_id は正しいようだが、 次のレコードの length = -1309404002 が不正、バイナリレコード自体にエラーがあるのか?
検索場所を変えてみた。最初のレコードは type=1、osm_id も正しく、このレコードは実在した。 しかし、次のレコードの length が巨大(異常)であった。
このlength はバイト単位のため、short配列のインデックス計算では length/2 とするのが漏れていた。
次には、エラーが最終タグと思われるところで起きる。例えば、葉ノード読み込みで読み込みデータが少し欠けているのではないか? リーフ長にはlength自身は含まれていなかった。
これで正常にパースできた。zorder算出はまだ実行していない。
パースは現在と同じ方法なので、時間も大差ない。SDカードの場合、読み込みはシリアライズするが、パース自体は並列処理ができる。 また、レンダリング時間は現在よりも多少高速化される見込みである。
やはり、検索結果には、都道府県の大きなポリゴン/マルチポリゴンが含まれる。行政名を書くだけの部分折れ線に分断すれば、 パフォーマンスは向上するが、姑息な気がするので、止めている。
殆どのタイルのレンダリングで、大きなポリゴンは除外されるが、境界線が当タイルを横切らないということを判定するのにもそれなりの 時間がかかる。
XY座標は次のようにしたので 0 から 1 の範囲におさまり、分かりやすい。
float fx = (float) Lib.lon2X(lon * Fn, 0); float fy = (float) Lib.lat2Y(lon * Fn, 0);
OSMほか多くの地図がメルカトル図法である。この場合、緯度に制限がある。
緯度の上限(北端): +85.05112878 度 緯度の下限(南端): -85.05112878 度
しかし、OSMデータ自体にはこの制限を超えるデータがある。 日本地図データではこの制限を超えるデータはないが、世界地図を対象とした陸地ポリゴンデータには 次ように、制限を超えるものがあるので、これを除去する。
(1619427034 -900000000) (1630572965 -889995000) (0.94984 Infinity) (0.003096 1.25453)
例えば -180 ~ 180 のモートンコードはそのままではうまく行かない。 0 ~ 360 にしてから行う。 ところが java では符号なし整数型がないため、360 * 107 = -694967296 となってしまう。
モートンコードは元のレコードの並び替えだけに使うので、106 を使えばしのげる。
早い段階から 0~1 の世界座標を Integer.MAX_VALUE(231-1)または 230倍して整数化する方法もある。 レンダリングとしては パフォーマンスはこの方が有利である。 デバッグでは、緯度、経度の方が分かりやすいので、変換がいる。
一時期では 230倍の整数化を使っていた。
とりあえずは、極座標のまま、モートンコードの算出だけ、 経度に 180度、緯度に 90度分のオフセットを加えて整数化した。
このモートンコード順に並び替えてから R-Tree を作成すると、 検索結果は大幅に改善した。
しかし、同じ葉ノードに、まだまだ、遠く離れたレコードが相当含まれている。 これはバグではなく、プログラムの特質によるものかも知れない。 世界全体からみれば、日本の陸地はごく小さい。このため、起きる現象かも知れない。 高ズームで必要になるのは日本領域のため、この範囲を先に R-Tree に登録して、 そのあと、残りの全てを登録すれば、実効速度は改善するであろう。
最初の登録で、HashSet に登録済みを記録しておき、次の登録ではこれを除外すればよい。 優先領域としては北海道、本州、四国、九州を含む矩形でいいだろう。 ここから外れたとしても検索時間が少し増える程度である。
陸地ポリゴンで、世界平面XY座標を試した。結果を下に示す。 該当する葉ノードはたったの一つで、これ以上良い解はない。
Rect box = new Rect(1395015420, 354146010, 1395015420+35000, 354146010+36000); 検索範囲 (0.88750 0.39468) (0.000010 0.000012) 0.0~1.0 Rect(952950464, 423780192 - 952960896, 423793344) 1<<30 を掛けた結果 総レコード数=122 1leafs 0.1MB 35mS
まず、これまでの結果を使って、陸地ポリゴンのみをレンダリングしてみる。
まず読み込み(空間検索)までを実装した。lands_high.obr が 400MB 程度ではあるが、 空間検索時間は 0~3mS程度であり、キャッシュが要らない速さである。
レンダリングは明日にする。
レンダリング結果(japan_7_113_50.webp)を下に示す。
陸地ポリゴンは単純であるが、OSMバイナリデータレコードの世界XY平面座標化は簡単ではない。
面積計算は極座標系の方が楽である。現在の Parser.java 単独wayオブジェクトによる面積計算と relation処理によって生まれるポリゴンの面積計算を別のプログラムで行っている。
差分コードのため、最終結果のレコードの座標データを極座標から平面座標に変換すると、 差分が2バイトで表せないケースがあるかも知れない。この場合の処理は面倒である。
もともと Parser.java は煩雑なプログラムであり、また、OSMタグの追加は面倒である。
もっと、わかりやすくしたいが、 この点、osm2pgsql のカスタマイズは非常に煩雑であるのと似ており、これは OSMの特質であり、避けられない 面もある。
急ぐ話ではないので、全般的に、プログラムを見直そう。
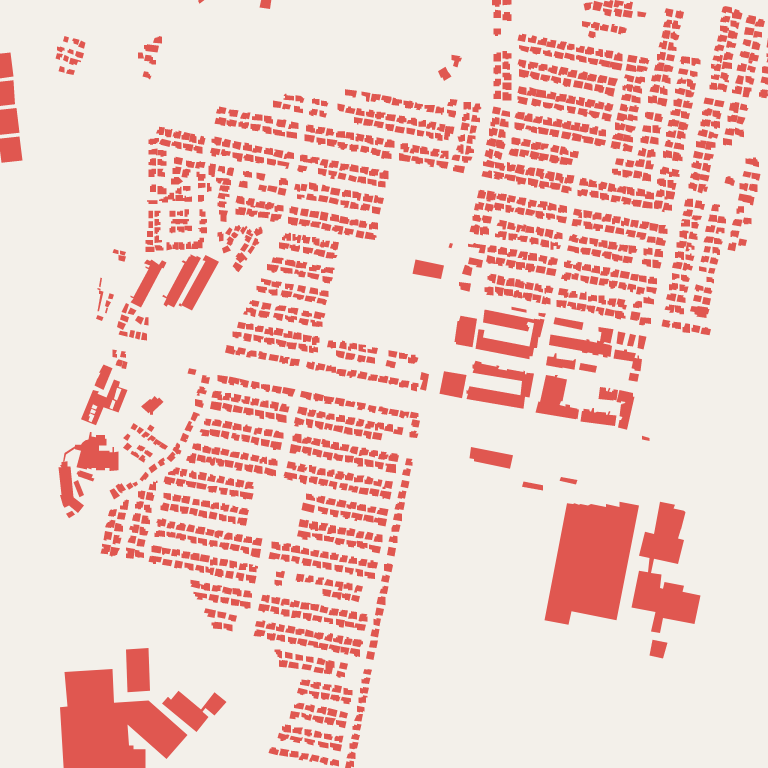
修正点は多岐に渡った。とりあえず、コンパイルエラーはとれたので、建物だけをレンダリング してみた。建物の色は分かりやすいように赤色にした。
バグは意外と少ないようで、一発で次の結果を得た。 座標値(zoom=15, x=29080, y=12915)に間違いはないことも確認した。
zoom 15 の住宅地域で、レコード数は 4000~8000程度となった。 レコードの検索・読み込み時間は 20~50mS 程度であった。最終的にはキャッシュをおく予定であるが、 キャッシュが要らないほどの速さである。
R-Tree & モートンコードの有効性を確認できたので、これで、全面的に書き換える。