MapnikによるOSMタイル地図作成で PostGIS が使われているが、十分に理解しているわけではない。 注意点を書き足していく。
前自作地図システムでは、病院などアイコンやテキスト(病院名)は敷地の中心点に C# プログラムで描画していた。
幾何学的重心は geometry ST_Centroid(geometry g1)関数で得られる。
当初はこの関数を使っていたが、いささか不都合がある。 凸多角形では幾何学的重心は必ず多角形内となるが、凸多角形以外ではこの重心が多角形内とは限らない。 例えば、三日月湖の幾何学的重心は三日月湖の外になる。
このため、多角形の中心は geometry ST_PointOnSurface(geometry g1)関数で求めるように変更した。 この関数で得られる点はかならず多角形内となる。
ただし、実行時間は大幅(正確に測定していないが数~十倍)に増加する。 また、必ずしも適切な位置とは思えないケースも散見された。
Mapnikも多角形内の位置が選ばれるが、 PostGISのST_PointOnSurface関数で得られる位置とは異なっており、どちらかといえば、 Mapnikの位置の方が適切である。
おそらく、PostGISは使わず、独自のアルゴリズムでこの位置を算出しているものと思われる。
余談になるが、pngファイルの出力についても、Mapnikは C#(.Net)よりも優れている。 Mapnikはかなり大きなソフトであるが、地図のレンダリングについては極めて優秀なソフトといえる。
穴ありポリゴンは最初が外枠(outer)の閉ループで、その後ろに穴(inner)の閉ループが続く[4]。 各innerは完全に outer に包含され、互いに交差してはならない。 閉ループは交差のない単純なものに限られる。先頭の頂点と末尾の頂点は同じもの。
下の Central Park は、最初が公園全体のポリゴン、次が池(reservoir)のポリゴンを表す。
INSERT INTO polys (name, geom)
VALUES ('Central Park',ST_GeomFromText('POLYGON(
(-73.973057 40.764356,-73.981898 40.768094,-73.958209 40.800621,-73.949282 40.796853,-73.973057 40.764356),
(-73.966681 40.785221,-73.966058 40.787674, ... , -73.965694 40.784457,-73.966681 40.785221)
)',4269));
OSMでは outer が複数のケースがあるのではなかろうか。その場合、MULTIPOLYGON[7] になるのだろうか。 実際の osmデータで確かめたい。
ざっと調べた限りでは、POLYGONのみであった。 おそらく、outer polygonが複数ある場合、osm2pgsql はレコードを複数にするのであろう。 その方がレンダリングが簡単でパフォーマンスもよい。
参照がほとんどで、かつほとんどのクエリでひとつのインデクスを使うようなテーブルのために、 PostgreSQLはCLUSTERコマンドを提供している[5]。
OSM地図システムの場合、Geomertry型カラム way は Null値を含まないはずなので、CLUSTERコマンドが使えるだろう。
例えば、次のようにする。
osm=# cluster planet_osm_line_index on planet_osm_line;
たしか、別のページに cluster planet_osm_line using planet_osm_line_index という記述があったので、 これでも同じであろう。
恐らく、osm2pgsql でインポートした場合、標準的な使い方では、CLUSTERコマンドを実行しなくても ベストな並びになっているのだろう。
しかし、インポート後にデータベースを修正すると、レコードの並びが変わってくる。 update文を実行すると、元のレコードには無効フラグが付けられ、新しいレコードが insert されるので、 並び順が変わってくる。
また、自前で新たに作成する my_osmdata テーブルなどは作成時点ではベストな並び順にはなっていないので、 CLUSTERコマンドの実行が有効に働くものと思われる。
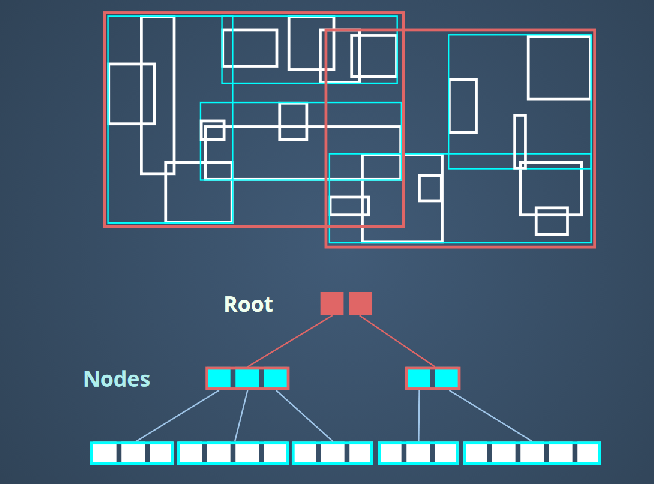
PostgreSQLのGiSTインデックスは総称であり、 PostGIS における GiSTインデックスはスライド[6]にある下のようなものらしい。 テーブルのGeometryカラムよりはやや小さいが、巨大なものとなっている。
この図は3階層であるが、実際の階層はレコード数に応じて、階層は深くなるのであろう。
ある矩形範囲(バウンディングボックス)のレコードを取り出す場合、最初に、Root が Shared_buffers に読み込まれ、 矩形と交差または矩形に包含されるものが抽出される。次に、該当 Nodes が Shared_buffers に読み込まれ、 矩形と交差または矩形に包含されるものが抽出される。何階層であっても再帰処理で同じことが行われる。 葉に到達して、レコードが決まる。
レコードのGeometryカラムの矩形(バウンディングボックス)との照合(交差または包含)はインデックスレベルで行えるのか、 該当レコードを Shared_buffers に読み込んでから行われるのかは分からない。
いずれにせよ、インデックスによる絞り込みで、該当レコードまたは該当8kBブロックが決まり、 テーブルのブロックが Shared_buffers に読み込まれる。
インデックスのサイズが巨大であることから察すると、例えば、首都圏のタイル地図をレンダリングするような場合、 その範囲には膨大なレコードが含まれるため、読み込まれるインデックスも膨大なものとなろう。
日本地図全体を西から東に順に描画するような場合、該当するインデックスの上位階層は緩やかに変化するため、 新たな読み込みは少なくてすむ。処理も効率よく行われるのであろう。 しかし、この描画が飛び飛びになると、新たなインデックスの読み込みも増え、インデックス走査にも時間がかかる。