恾侾丏幆暿巕傪擣幆偡傞桳尷僆乕僩儅僩儞
宍幃尵岅偲僆乕僩儅僩儞偺娭學傪徻偟偔弎傋傞偨傔偵丄僠儑儉僗僉乕偺暘椶傪嵞宖偟偰偍偔丅
| 僞僀僾 | 暥朄 | 僆乕僩儅僩儞 | 尵岅椺 |
|---|---|---|---|
| 侽宆 | 嬪峔憿暥朄 | 僠儏乕儕儞僌儅僔儞 | 帺慠尵岅 |
| 侾宆 | 暥柆埶懚暥朄 | 慄宍桳奅僆乕僩儅僩儞 | |
| 俀宆 | 暥柆帺桼暥朄 | 僾僢僔儏僟僂儞僆乕僩儅僩儞 | 僾儘僌儔儉尵岅 |
| 俁宆 | 惓婯暥朄 | 桳尷僆乕僩儅僩儞 | 懱宯壔偟偨僐乕僪側偳 |
幆暿巕乮曄悢柤丄娭悢柤側偳乯偺峔暥婯懃偼師偺傛偆偵惓婯暥朄偵傛傝掕媊偱偒傞[1]丅
亙幆暿巕亜丂::亖丂亙塸帤亜 乷 亙塸悢帤亜 乸 亙塸悢帤亜丂::亖丂亙塸帤亜 | 亙悢帤亜 亙塸帤亜丂 ::亖丂a | b | 乧 | z | A | B | 乧 | Z 亙悢帤亜丂 ::亖丂0 | 1 | 2 | 乧 | 9
偙偙偱 乷 亙塸悢帤亜 乸 偼 亙塸悢帤亜 偑侽屄埲忋暲傫偩傕偺傪昞偡丅 戞俀夞偺庼嬈偱偺婰朄傪巊偊偽丄( 亙塸悢帤亜 )* 偲側傞丅
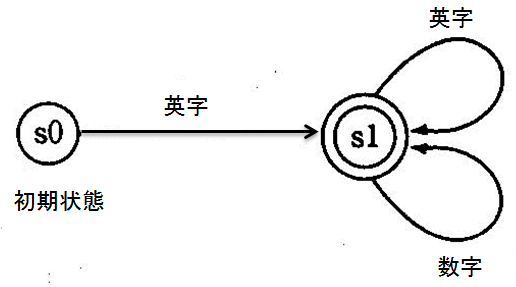
惓婯暥朄偵傛傝掕媊偝傟偨峔暥偼桳尷僆乕僩儅僩儞(finite automaton)偵傛偭偰擣幆偡傞偙偲偑偱偒傞丅 桳尷僆乕僩儅僩儞偼丄桳尷屄偺忬懺偲忬懺娫偺慗堏傪婎杮奣擮偲偡傞擣幆婡夿偱偁傞丅 弶婜忬懺偐傜弌敪偟丄擖椡岅拞偺婰崋傪侾偮偢偮撉傒崬傒丄忬懺慗堏傪師乆偵孞傝曉偟丄 擖椡岅偑擣幆偝傟傞偐偳偆偐傪挷傋傞丅忋偺峔暥婯懃偱掕媊偝傟傞幆暿巕傪擣幆偡傞 桳尷僆乕僩儅僩儞傪恾侾丏偵帵偡丅恾拞丄仜偼忬懺傪昞偟丄栴報偼忬懺慗堏傪昞偡丅
弶婜忬懺s0偱塸帤傪撉傒崬傓偲丄忬懺s1偵慗堏偡傞丅 s1偱偼丄塸帤傑偨偼悢帤偺撉傒崬傒偵傛偭偰帺暘帺恎傊慗堏偡傞丅 忬懺s1偑仢偵側偭偰偄傞偺偼丄偦傟偑幆暿巕傪擣幆偟偨忬懺偵側偭偰偄傞偙偲傪昞偟偰偄傞丅
偙偺桳尷僆乕僩儅僩儞偺悢妛儌僨儖偼 <儼, S, s0, 兟, F> 偺5梫慺偐傜峔惉偝傟傞丅
僾儘僌儔儈儞僌尵岅偺峔惉梫慺偼幆暿巕偺傎偐丄 梊栺岅乮C尵岅偱尵偊偽丄int, if, for, struct側偳乯丄墘嶼巕丄婰崋丄悢抣側偳偑懚嵼偡傞偑丄 偄偢傟傕丄惓婯暥朄偱掕媊偡傞偙偲偑偱偒傞丅 偟偨偑偭偰丄僐儞僷僀儔傗僀儞僞僾儕僞偺帤嬪夝愅僼僃乕僘偱偼丄 偙偺傛偆側桳尷僆乕僩儅僩儞偵懳墳偡傞張棟儊僇僯僘儉傪壗傜偐偺宍偱幚尰偡傟偽傛偄丅