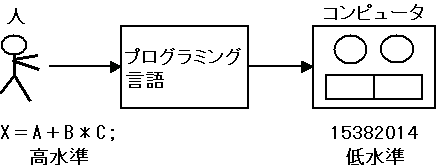
コンパイラは高水準言語(高級言語)によるプログラムを計算機に分かる機械語に翻訳する。
コンパイラはC言語やJavaなど高水準言語で開発できるが、 機械語コードを生成するためには、対象とするコンピュータの機械語命令についての知識が不可欠である。
また、Windowsパソコンの実行可能形式ファイル(または実行可能ファイル) を生成するには、Portable Executable(PE)形式についても知らねばならない。 しかし、既存のアセンブラーを使うのであれば、アセンブリ言語のコードを生成するまでが、 コンパイラの仕事となる。
インタプリタは、同時通訳のようにプログラムを一行ずつ即実行するもの。 インターネットでの代表例はJavaScript言語である。ただし、JavaScriptは、C言語、Javaと同様の 構造化プログラミング言語であるから、インタプリタではソースプログラムを直ちに一行ずつ 実行できるわけではない。まず、字句解析、構文解析を行い、意味解析・実行を行うこととなる。 インタプリタの開発では、機械語の知識は必要としない。 プログラムの実行速度は通常、コンパイラで生成した機械語プログラムより桁違いに遅い。
プログラムの処理過程(プログラムの開発手順)を次図に示す。
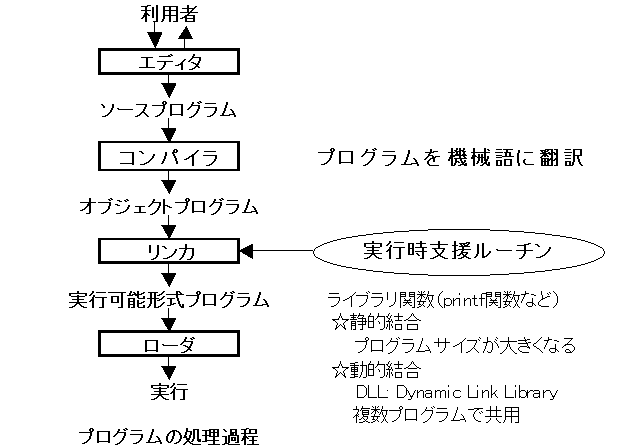
コンパイラの構造はしばしば、字句解析、構文解析、意味解析、コード生成の4フェーズで表現される。 しかし、実際に、コンパイラを設計・開発する場合、 まず、プログラミング言語の仕様を決め、表現しなければならない。 また、コード生成で終わりではない。規格に沿って、実行可能形式ファイルを生成しなければならない。 パソコンは長足の進歩を遂げており、諸規格も高度化しているので、 実行可能形式ファイルの生成はいとも簡単とは言えない。
X=A+B*C; ⇒ X, =, A, +, B, *, C, ;
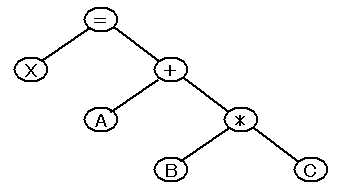
LOAD B ・・・・・・ B の内容をレジスタへ ( レジスタ ← B ) MULT C ・・・・・・ C の内容と乗じる ( レジスタ ← レジスタ*C ) ADD A ・・・・・・ A を加える ( レジスタ ← レジスタ+A ) STORE X ・・・・・・ 結果を X へ ( X ← レジスタ )最終的には数字列(バイナリデータ)に変換される。
字句解析から始まり、構文解析、意味解析、中間語コード生成まで コンパイラとインタプリタに大きな違いはない。
両者の違いは、その後にある。 コンパイラの場合、中間語(もしくはアセンブリ言語)コードを機械語コードに変換し、 実行可能形式ファイルを生成する。 一方、インタプリタは中間語コードをそのまま一命令ずつ解釈・実行する。
実行可能形式ファイルは前に 簡単に紹介したように、複雑な構造(Portable Executable Format)をしている。 8ビット、16ビットパソコン時代には、COM形式と呼ばれる簡単な形式の実行可能ファイルも存在したが、 32ビットパソコンでは、拡張子が com であっても、内容はPE形式である。
このため、制作演習では、最初にインタプリタを取り上げ、理解が深まってから、 コンパイラ版の制作に進む。
一般に、インタプリタでの中間言語コードとコンパイラでの中間言語コードは全く同じとは限らない。 コンパイラの場合、いずれ、機械語コードに変換しなければならないので、 機械語命令を意識したものになるが、インタプリタでは、機械語を殆ど意識しなくてもよい。