僐儞僷僀儖夁掱忋偺戞俀偺僼僃乕僘偱偁傞峔暥夝愅偵偮偄偰愢柧偡傞丅 峔暥夝愅偺曽朄偼丄戝偒偔偼壓岦偒(top-down)夝愅朄偲忋岦偒(bottom-up)夝愅朄偵暘椶偝傟傞丅
壓岦偒(top-down)峔暥夝愅朄偼峔暥夝愅栘偺崻偐傜巒傔偰壓偵岦偐偆丅 峔暥婯懃偵慺捈偵懳墳偟偨夝愅朄偱偁傞丅
嵞婣揑壓岦偒夝愅朄乮嵞婣崀壓朄乯偼丄峔暥婯懃忋偺奺旕廔抂婰崋偵偮偄偰丄 傂偲偮偢偮嵞婣揑側張棟傪懳墳偝偣丄偙偺庤懕偒偺廤傑傝偵傛偭偰峔暥夝愅傪峴偆丅 夝愅僾儘僌儔儉偼峔暥婯懃傪彂偒壓偟偨傕偺偲側傞丅
墘嶼巕偑仏偲亄偺峔暥婯懃偼壓乮峔暥婯懃丂A乯偺傛偆偵昞偟偨応崌丄 偦傟帺恎傪嵞傃嵍偐傜巊偭偰掕媊偝傟偰偄傞乮嵍嵞婣揑乯丅 偙傟傪偦偺傑傑僾儘僌儔儉壔偡傞偲丄夝愅偑柍尷儖乕僾偵娮傞丅
峔暥婯懃丂A丏 丂丂<幃>丂::=丂<幃>丂亄丂<崁> | <崁> 丂丂<崁>丂::=丂<崁> 仏 <曄悢> | <曄悢>
師偺傛偆側摍壙側峔暥婯懃偵抲偒姺偊傞偙偲偵傛傝丄 柍尷儖乕僾偺栤戣偑夞旔偱偒傞丅 偙偙偱丄{ X } 偼 X 偑 0 屄埲忋暲傫偩傕偺傪昞偡丅
峔暥婯懃丂B丏
丂丂<幃>丂 ::=丂<崁>乷 亄丂<崁> 乸 丂丂丂丂丒丒丒 (1)
丂丂<崁>丂 ::=丂<曄悢> { 仏 <曄悢> 乸 丒丒丒 (2)
丂丂<曄悢>丂::=丂a | b | c 丒丒丒 (3)
偙偙偱偼丄嶲峫傑偱偵峔暥婯懃 A. 傪帵偟偨丅 婯懃 A. 偐傜婯懃 B. 偵曄姺偡傞偺偱偼側偔丄嵟弶偐傜丄婯懃 B. 傪峫偊傞曽偑偄偄丅
椺偊偽丄
B * C + D / E偺応崌丄*丄/ 偑 +丄- 傛傝桪愭弴埵偑崅偄偐傜 B*C 偍傛傃 D/E 傪傂偲夠偲偟偰丄
(B*C) +
(D/E) 偺傛偆偵懆偊傞丅
僩僢僾僟僂儞揑偵偼丂<幃> ::=丂<崁>丂亄丂<崁> 偲側傞丅
*丄/ 偼偁偭偨偲偟偰傕丄亄丄亅 偑側偄傛偆側働乕僗偼 <幃> ::=丂<崁> 偲彂偔丅
亄偑擇偮偺応崌丄<幃> ::=丂<崁>丂亄丂<崁>丂亄丂<崁> 偲側傞丅
亄偺悢偼侽屄埲忋擟堄偺悢偵側傞偨傔丄婯懃 B. 偺 (1) 偺傛偆偵彂偔丅
峔暥婯懃偼墘嶼巕偺桪愭弴埵偑掅偄弴偵彂偔丅 偙偺偙偲偐傜 (2) 偼娙扨偵棟夝偱偒傞丅亄偲仏偼嫟偵俀崁墘嶼偺偨傔偵丄慡偔摨偠宍偲側傞丅
仏傛傝傕峏偵桪愭弴埵偑崅偄 <曄悢> 偼擇崁墘嶼偱偼側偄偨傔丄彂偒曽偼曄傢傞丅
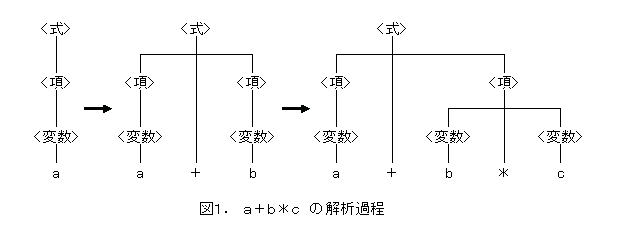
a + b * c 偺夝愅夁掱傪愢柧偡傞丅 忋偺峔暥婯懃偼墘嶼巕 仏 偼墘嶼巕 亄 傛傝傕桪愭弴埵偑崅偄偙偲傪昞偟偰偄傞丅
捠忢偺僐儞僷僀儔偱偼丄偙偺夝愅夁掱偱僣儕乕峔憿偺僨乕僞乮峔暥夝愅栘乯 傪惗惉偟丄峔暥夝愅埲崀偺僼僃乕僘偱偁傞堄枴夝愅丄僐乕僪惗惉偱巊梡偡傞丅 僾儘僌儔儈儞僌尵岅偺巇條偑尷掕揑側応崌丄忋弎偺峔暥夝愅偺僼僃乕僘偱丄 暪峴偟偰丄堄枴夝愅丄僐乕僪惗惉傪峴偆偙偲偑偱偒傞偺偱丄 僣儕乕峔憿偺僨乕僞惗惉偼昁恵偱偼側偄丅
峔暥夝愅栘傪丄枛抂偺梩偵懳墳偡傞擖椡僩乕僋儞楍偐傜巒傑偭偰丄師乆偲忋岦偒偵 栘偺崻偺曽偵岦偐偭偰嶌偭偰偄偔曽朄偑忋岦偒(bottom-up)峔暥夝愅朄偱偁傞丅 峔暥婯懃偱尵偊偽丄塃曈偺婰崋楍傪嵍曈偱抲偒姺偊側偑傜乮娨尦偟側偑傜乯丄 奐巒偺旕廔抂婰崋傊偲岦偐偭偰張棟傪偟偰偄偔丅 埲壓丄忋岦偒峔暥夝愅朄偺傂偲偮偱偁傞墘嶼巕弴埵暥朄偵偮偄偰愢柧偡傞丅
A ::= 乧 B C 乧A, B, C 偼旕廔抂婰崋丅
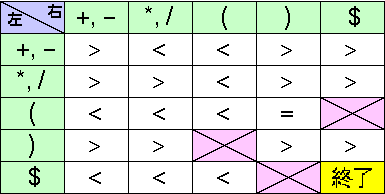
<, >, = 偺偆偪偨偐偩偐侾屄偺娭學偟偐惉傝棫偨側偄丅
::= ( <幃> ) 丒丒丒丂
( 偲 ) 偺桪愭弴埵偼摨偠丅
懄偪 ( = )
椺丗丂<幃> ::= <幃> + <崁> 丂丂丂<崁> ::= <場巕> * <崁>偙偺応崌 + < *
椺丗丂<場巕> ::= ( <幃> ) 丂丂丂<幃> ::= <幃> + <崁>偙偺偲偒丂+ > )
丒 a = b : A 仺丂乧ab乧 傑偨偼 A 仺 乧aBb乧
丒 a < b : B 仺 乧aA乧偲偄偆惗惉婯懃偑懚嵼偟丆A 仺 b乧 傑偨偼 A 仺 Cb乧
丒 a > b : B 仺 乧Ab乧偲偄偆惗惉婯懃偑懚嵼偟丆A 仺 乧a 傑偨偼 A 仺 乧aC
偨偩偟丆彫暥帤偼廔抂婰崋丆戝暥帤偼旕廔抂婰崋
丒幃傪$偲$偱埻傓丅$ 偺弴埵傕昁梫丅 丒杮棃偼乽悢帤乿乽幆暿巕乿偵傕弴埵偼懚嵼 乮屻偱弎傋傞傾儖僑儕僘儉偱偼晄梫乯
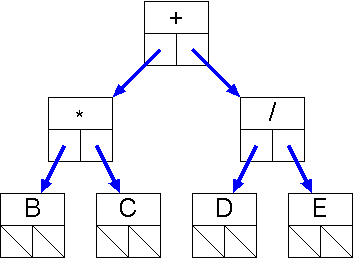 |
B * C + D / E 巐偮慻偵傛傞昞尰 (*, B, C, T1) (/, D, E, T2) (+, T1, T2, T3) |
|---|
墘嶼巕弴埵朄偼僔儞僾儖偩偑丄堦斒揑側尵岅偺峔暥夝愅偵偼岦偐側偄丅
LR朄偼擖椡傪嵍偐傜塃傊憱嵏偟丄嵟塃偺婯懃傪摫偔丅 LR峔暥夝愅偼擖椡偲僗僞僢僋丄峔暥夝愅昞偐傜側傞丅
峔暥夝愅昞偺嶌傝曽偼偙偙偱偼徣棯偡傞丅 椺偊偽 嶲峫暥專[3]偵弎傋傜傟偰偄傞丅
擖椡偼侾婰崋偢偮嵍偐傜塃偵撉傓丅僗僞僢僋偵偼丄
丂s0 X1 s1 X2 s2 X3 s3.... Xm sm偲偄偆婰崋楍傪愊傓丅倱偼忬懺偵懳墳偟偨婰崋偱偁傞丅 倃偼暥朄婰崋偱丄幚嵺偼昁梫側偄偑愢柧偺偨傔偵壛偊偰偁傞丅 峔暥夝愅昞偼峔暥夝愅摦嶌娭悢ACTION 偲峴偒愭娭悢GOTO偺俀偮偺晹暘偐傜側傞丅 LR峔暥夝愅偺僾儘僌儔儉偼尰嵼偺僗僞僢僋偺嵟忋抜偺忬懺sm偲擖椡婰崋ai傪傕偪偄偰丄 ACTION[sm, ai]傪堷偄偰丄埲壓偺摦嶌偺偳傟偐傪偲傞丅
悢幃偺暥朄
(1) Expr 仺 Expr '+' Term
(2) Expr 仺 Term
(3) Term 仺 Term '*' Factor
(4) Term 仺 Factor
(5) Factor 仺 '(' Expr ')'
(6) Factor 仺 identifier
偺峔暥夝愅昞偼師偺傛偆偵側傞丅
a * b + c 偲偐 (2 + 3)*4 偼偙偺暥朄傪枮偨偟偰偄傞丅
SLR(simple LR)朄偱偼丄暥朄傛傝丄師偺傛偆側峔暥夝愅昞傪嶌傝丄 偦傟傪梡偄偨僆乕僩儅僩儞偱峔暥夝愅傪偡傞丅
| ACTION | GOTO (旕廔抂婰崋) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| state | id | + | * | ( | ) | $ | E | T | F |
| 0 | s5 | s4 | 1 | 2 | 3 | ||||
| 1 | s6 | acc | |||||||
| 2 | r2 | s7 | r2 | r2 | |||||
| 3 | r4 | r4 | r4 | r4 | |||||
| 4 | s5 | s4 | 8 | 2 | 3 | ||||
| 5 | r6 | r6 | r6 | r6 | |||||
| 6 | s5 | s4 | 9 | 3 | |||||
| 7 | s5 | s4 | 10 | ||||||
| 8 | s6 | s11 | |||||||
| 9 | r1 | s7 | r1 | r1 | |||||
| 10 | r3 | r3 | r3 | r3 | |||||
| 11 | r5 | r5 | r5 | r5 | |||||
C尵岅偵傛傞峔暥夝愅僾儘僌儔儉傪埲壓偵帵偡丅幚峴寢壥傪壓偺塃偵帵偡丅
|
( 1) input=id state= 0 action= 5: shift push( 5) ( 2) input= * state= 5 action=-6: reduce LR[0][8] push( 3) ( 3) input= * state= 3 action=-4: reduce LR[0][7] push( 2) ( 4) input= * state= 2 action= 7: shift push( 7) ( 5) input=id state= 7 action= 5: shift push( 5) ( 6) input= + state= 5 action=-6: reduce LR[7][8] push(10) ( 7) input= + state=10 action=-3: reduce LR[0][7] push( 2) ( 8) input= + state= 2 action=-2: reduce LR[0][6] push( 1) ( 9) input= + state= 1 action= 6: shift push( 6) (10) input=id state= 6 action= 5: shift push( 5) (11) input= $ state= 5 action=-6: reduce LR[6][8] push( 3) (12) input= $ state= 3 action=-4: reduce LR[6][7] push( 9) (13) input= $ state= 9 action=-1: reduce LR[0][6] push( 1) (14) input= $ state= 1 action=9999: 庴棟! |
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define x 9998
#define A 9999 // 庴棟
char *token[] = { "id", "+", "*", "(", ")", "$" };
int LR[][] = {
// 0 1 2 3 4 5 6 7 8
// id + * ( ) $ E T F
{ 5, x, x, 4, x, x, 1, 2, 3 }, // 0
{ x, 6, x, x, x, A, x, x, x }, // 1
{ x,-2, 7, x,-2,-2, x, x, x }, // 2
{ x,-4,-4, x,-4,-4, x, x, x }, // 3
{ 5, x, x, 4, x, x, 8, 2, 3 }, // 4
{ x,-6,-6, x,-6,-6, x, x, x }, // 5
{ 5, x, x, 4, x, x, x, 9, 3 }, // 6
{ 5, x, x, 4, x, x, x, x,10 }, // 7
{ x, 6, x, x,11, x, x, x, x }, // 8
{ x,-1, 7, x,-1,-1, x, x, x }, // 9
{ x,-3,-3, x,-3,-3, x, x, x }, // 10
{ x,-5,-5, x,-5,-5, x, x, x }, // 11
};
int r2n[] = { 6, 6, 7, 7, 8, 8 }; // rule斣崋仺LR昞偺楍斣崋
int pops[] = { 3, 1, 3, 1, 3, 1 };
int stack[100];
int sp = 0;
void push(int s) { stack[sp++] = s; }
int peek() { return sp > 0 ? stack[sp-1] : x; }
int pop() { return sp > 0 ? stack[--sp] : x; }
int tokenNumber(char *str) {
int n;
for (n = 1; n < sizeof(token)/sizeof(char*); n++)
if (strcmp(str, token[n]) == 0) return n;
return 0; // identifier or number
}
void main() {
//char *input[] = { "(", "2", "+", "3", ")", "*", "5", "$" };
char *input[] = { "a", "*", "b", "+", "c", "$" };
int ix, c, n, step, state, action;
ix = 0;
c = tokenNumber(input[ix++]);
push(0); // 弶婜忬懺傪僾僢僔儏
for (step = 1;;step++) {
state = peek();
action = LR[state][c];
printf("(%2d) input=%2s state=%2d action=%2d: ",
step, token[c], state, action);
if (action == x) {
exit(1); // 僄儔乕廔椆
} else if (action == A) {
printf("庴棟!\n");
exit(0);
} else if (action >= 0) { // shift: 師偺忬懺傪僗僞僢僋偵愊傓
push(action);
printf("shift %9s push(%2d)\n", "", action);
c = tokenNumber(input[ix++]);
} else { // action < 0 // reduce:
for (n = pops[-action-1]; n-- > 0; ) pop();
state = LR[peek()][r2n[-action-1]];
printf("reduce LR[%d][%d] push(%2d)\n",
peek(), r2n[-action-1], state);
push(state);
}
}
}